Storage and Retrieval
In this doc, we discuss how we store and retrieve data from the database's perspective. It's important to understand and choose the storage engine that will fit best with your application.
The biggest difference in choosing a database is whether it's optimized for transactional workloads or for analytics.
Data Structures Powering Databases
Writing/appending to files is a very efficient operation. Many databases internally use a log which is an append-only file which stores sequence of records.
To retrieve a particular record from a database, we need an index data structure. The basic idea of an index is to keep some additional metadata, derived from the primary data, that acts as a signpost. Adding an index slows down the writes since it incurs an overhead because the index needs to be updated every time data is written.
This is an important trade-off in storage systems. Indexes speed up reading but every index slows down writing. For this reason, databases don't index every by default and allow the administrator to do so.
Hash Indexes
Key-value, dictionary stores internally implement a hash map. When a new object is stored in the dictionary, the hash function appends a byte offset to the key to help locate the value.
A log is usually also cut up into segments of a certain size. When a record with the same key value is appended to the log segment, a compaction process occurs where the older record is disposed and replaced by the new record. This ensures there are no duplicates.
Hash indexes are a well-suited solution for when the keys are updated frequently. And there are not too many distinct keys kept in memory.
If the hash table doesn't fit in memory or you require range queries, hash indexes are not a good solution.
SSTables and LSM-Trees
Sorted String Tables sort the key-value pairs by key. A few advantages of SSTables over log segments with hash indexes:
- Merging of segments, using a merge sort, is simple and efficient.
- There's no need to have indexes of all the keys in-memory since the segments are sorted. When trying to find a particular key in the file, we can find an offset of a key (that is available in memory) that is close to the one we're looking for and search for it from there. We save in-memory allocation.
- As a result of the above, reading require scanning several key-value pairs ranges. This gives us the opportunity to compress the range into a block and write it to disk. Then each entry points to the start of a compressed block. This saves disk space and reduces I/O bandwidth use.
SSTables use red-black or AVL trees under-the-hood to read unsorted incoming writes and read them back sorted.
When a write comes in, it's added to an in-memory tree called a memtable. When the memtable gets bigger in size than some threshold (e.g. 5MB), it's written out to disk and other writes are written to the memtable. The most recent segment of the database is the most recent file written to disk.
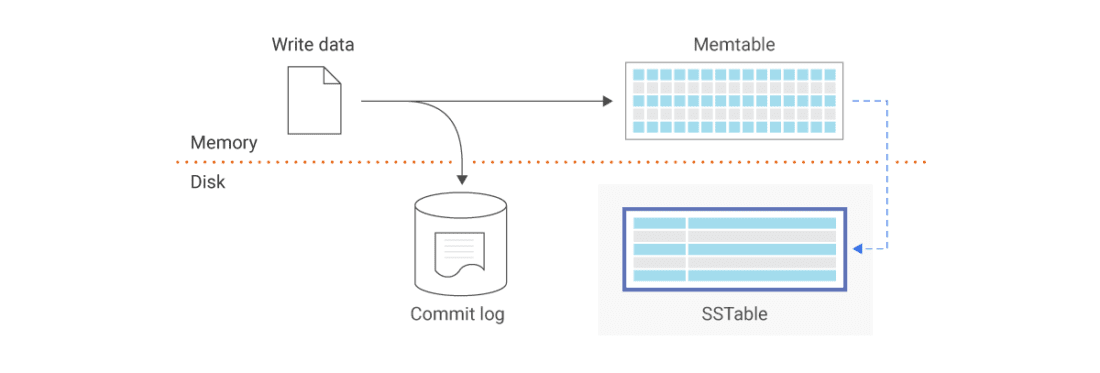
To serve a read request, try to find the key in the memtable then in the most recent on-disk segment.
RocksDB and Cassandra use SSTables.
SSTables and Log-Structured Merge-Trees (LSM-Trees) both have this indexing structure. Storage engines that based on merging and compacting sorted files are referred to as LSM storage engines such as Lucene/Elasticsearch.
B-Trees
The most common indexing in relational databases, and some non-relational databases, technique is the B-tree.
Like SSTables, B-trees keep key-value pairs sorted by key, allowing for k-v lookups and range queries.
B-Trees, mimicing the hardware, break down the database into fixed-size blocks or pages (usually 4KB in size) and read/write one page at a time. Pages are identified using an address and have pointers to each other.
To search for a key, we first hit the root page of the B-Tree which contains references to child pages. Each child page is responsible for a continuous range of keys. Once we get to the last page (leaf page), we get the value of the key. To protect from race conditions, in case multiple threads concurrently attempt to access the tree, latches (lightweight locks) are used.
To add a new key, we find the page where the key is supposed to be saved. If there's not enough room for it, it's split into 2 new, half-full pages and a reference is added to those pages in the original page.
To update an existing key, we reach the leaf page, change the value in that page and then write that page to disk.
The number of references to child pages in one page of the B-Tree, typically in the several hundreds, is called the branching factor.
Most databases fit into a B-tree that is 3 to 4 levels deep (4 level tree of 4KB pages with 500 branching factor stores 256TB).
To make B-Trees reliable and resilient to crashes, they implement a write-ahead log (WAL) data structure on disk. This is an append-only file used that is written before any writes are done to the tree. It's used to restore the tree in case a database crashes.
Performance
B-trees are typically known to be faster for reads whereas LSM-trees are known to be faster for writes.
Write amplification is the sum of all one write operation to a database's lifetime that resulted in multiple writes. For example, when a record is inserted into either B or LSM tree results in writing to the WAL and the tree itself (B-tree) or compaction/merge (LSM-tree). In write-heavy applications, write amplification means that the more the engine writes, the less writes it can perform on disk.
LSM-Trees have more efficient use of disk space since there's no halving of blocks that leave fragmented/empty block space.
Reading from LSM-Trees depends on disk and I/O resources since there could be a heavy compaction process that needs to happen at the time of reading. This affect response times. The larger the database becomes, the more disk bandwidth is required for compaction.
As RAM becomes cheaper, it might become more feasible to have the dataset entirely in memory. For in-memory databases such as Memcached nad Redis, the data is ephermal (it's okay for the data to be lost) as its used for caching only. The in-memory database loads it's state from disk or network (from a replica).
Transaction or Analytics?
A transaction is a group of reads and writes and uses a pattern known as online transaction processing (OLTP).
In data analytics, a query needs to scan a large number of records and run some calculation over them. Data analytics uses a pattern known as online analytic processing (OLAP).
| Property | OLTP | OLAP |
|---|---|---|
| Main read pattern | Small number of records per query, fetched by key | Aggregate large number of records |
| Main write pattern | Random-access, low-latency writes from user input | Bulk import (ETL) or event stream |
| Primarily used by | End user/customer, via web app | Internal analyst, for decision support |
| What data represents | Latest state of data (current point in time) | History of events that happened over time |
| Dataset size | GB/TB | TB/PB |
Data Warehousing
A Data warehouse is a separate database from the rest of the databases that analysts can query to freely without affecting the OLTP operations. It contains a read-only copy of the data in all the OLTP systems in the company.